IBM Informix: Leistungsstarke Datenbank für moderne Anforderungen
In der heutigen datengetriebenen Welt stehen Unternehmen vor der Herausforderung, massive Mengen an Informationen in Echtzeit zu verarbeiten, zu speichern und zu analysieren. IBM Informix hat sich über Jahrzehnte hinweg als eine der zuverlässigsten und effizientesten Datenbanklösungen am Markt etabliert. Während andere Systeme oft an Komplexität scheitern, besticht Informix durch seine legendäre „Set-it-and-forget-it“-Mentalität. Diese Datenbank ist nicht nur ein Relikt der IT-Geschichte, sondern ein hochmodernes Werkzeug, das speziell für die Anforderungen von Edge Computing, dem Internet der Dinge (IoT) und hybriden Cloud-Umgebungen optimiert wurde. In diesem umfassenden Guide erfahren Sie, warum Informix auch im Jahr 2026 die erste Wahl für unternehmenskritische Anwendungen bleibt.
Einleitung: Stärken von IBM Informix

IBM Informix ist weit mehr als nur ein relationales Datenbankmanagementsystem (RDBMS). Es ist eine vielseitige Datenplattform, die sich durch eine extrem geringe Administrationstiefe und eine außergewöhnliche Performance auszeichnet. Seit seiner Entstehung hat sich Informix kontinuierlich weiterentwickelt, um den wechselnden Anforderungen der IT-Landschaft gerecht zu werden. Heute wird es von globalen Konzernen ebenso geschätzt wie von mittelständischen Unternehmen, die eine robuste Lösung für ihre Warenwirtschaft, Logistik oder Fertigungssteuerung benötigen. Die Architektur von Informix ermöglicht es, sowohl strukturierte als auch unstrukturierte Daten nahtlos in einem einzigen System zu verwalten, was in der modernen Anwendungsentwicklung einen entscheidenden Vorteil darstellt.
Einer der größten Pluspunkte von Informix ist die Skalierbarkeit. Ob auf einem winzigen Raspberry Pi in einer Industrieanlage oder auf einem leistungsstarken Multi-Node-Cluster im Rechenzentrum – die Engine bleibt dieselbe. Diese Konsistenz ist besonders im Bereich des Edge Computings wertvoll. Laut einer Analyse von Gartner wird die Datenverarbeitung außerhalb traditioneller Rechenzentren massiv zunehmen, und Informix ist hierfür durch seinen geringen Ressourcenverbrauch prädestiniert. Während Konkurrenzprodukte oft gigantische Mengen an Arbeitsspeicher und CPU-Zyklen verschlingen, arbeitet Informix hocheffizient und liefert dennoch Antwortzeiten im Millisekundenbereich.
Ein weiterer Aspekt ist die Hochverfügbarkeit. Mit Funktionen wie High-Availability Data Replication (HDR) und Remote Standby Secondary (RSS) stellt Informix sicher, dass geschäftskritische Prozesse niemals stillstehen. In einer Zeit, in der jede Minute Ausfallzeit tausende Euro kosten kann, bietet Informix eine Sicherheitsebene, die durch automatische Failover-Mechanismen und unterbrechungsfreie Updates ergänzt wird. Die Fähigkeit, Datenbank-Schemata im laufenden Betrieb zu ändern (Online Schema Evolution), ist ein Merkmal, das Administratoren weltweit schätzen, da Wartungsfenster so auf ein Minimum reduziert werden können.
Die Vielseitigkeit von Informix zeigt sich auch in der Unterstützung moderner Programmiersprachen und Frameworks. Egal ob Java, Python, .NET oder Node.js – die Integration ist dank standardisierter Treiber und APIs denkbar einfach. Dies führt uns direkt zum nächsten wichtigen Punkt: der Architektur und den zugrunde liegenden Datenmodellen, die Informix so einzigartig machen.
Kernfunktionen und Datenmodelle
Das Herzstück von IBM Informix ist seine Multi-Engine-Architektur, die es ermöglicht, unterschiedliche Datentypen nativ zu verarbeiten. Während klassische relationale Datenbanken oft Probleme mit unstrukturierten Daten haben, nutzt Informix ein objekt-relationales Modell. Das bedeutet, dass neben Tabellen und Spalten auch komplexe Datentypen wie Zeitreihen (TimeSeries), Geodaten (Spatial) und JSON-Dokumente hocheffizient gespeichert werden können. Diese Hybrid-Fähigkeit macht Informix zu einem „Swiss Army Knife“ der Datenverwaltung.
Besonders hervorzuheben ist die TimeSeries-Technologie. In der Industrie 4.0 fallen sekündlich Millionen von Sensordaten an. Herkömmliche Datenbanken stoßen hier schnell an ihre Grenzen, da die Indizierung und Speicherung dieser flüchtigen Daten enorme Ressourcen frisst. Informix hingegen speichert Zeitreihen in speziellen Containern, die den Speicherplatzbedarf um bis zu 60% reduzieren und die Abfragegeschwindigkeit um den Faktor 10 oder mehr steigern können. Laut IBM ermöglicht dies Analysen in Echtzeit, die zuvor Stunden gedauert hätten.
Ein weiteres Highlight ist die Unterstützung von NoSQL. Viele Entwickler bevorzugen heute die Flexibilität von JSON-Dokumenten, wie man sie von MongoDB kennt. Informix bietet eine native JSON/BSON-Schnittstelle, die es erlaubt, Dokumente direkt über die MongoDB-API abzufragen, während sie im Hintergrund in einer ACID-konformen relationalen Umgebung gespeichert werden. Dies kombiniert die Agilität der NoSQL-Welt mit der Zuverlässigkeit und Transaktionssicherheit einer klassischen Enterprise-Datenbank. Unternehmen müssen sich also nicht mehr zwischen „schnell und flexibel“ oder „sicher und strukturiert“ entscheiden – Informix bietet beides gleichzeitig.
Vergleich der Datenmodelle in Informix
Zusammenfassend lässt sich sagen, dass die technologische Basis von Informix so konzipiert ist, dass sie mit den Daten wächst und sich an neue Formate anpasst. Diese Flexibilität führt dazu, dass der Installations- und Einrichtungsprozess oft der erste Berührungspunkt ist, an dem Administratoren die Effizienz des Systems spüren.

Installation und Ersteinsatz

Die Installation von IBM Informix ist im Vergleich zu anderen Enterprise-Datenbanken erstaunlich unkompliziert. IBM bietet verschiedene Editionen an, von der kostenlosen Community Edition für Entwickler bis hin zur Enterprise Edition für unbegrenzte Skalierbarkeit. Ein besonderes Merkmal ist der geringe Footprint: Ein voll funktionsfähiger Informix-Server kann innerhalb weniger Minuten auf fast jedem Betriebssystem, sei es Linux, Windows, AIX oder macOS, aufgesetzt werden.
Der Installationsprozess wird heute oft über Container-Technologien wie Docker oder Kubernetes abgewickelt. IBM stellt offizielle Images zur Verfügung, die vorkonfiguriert sind und sofort in eine Microservices-Architektur integriert werden können. Dies reduziert die typischen „In meinem System funktioniert es“-Probleme und beschleunigt den Deployment-Zyklus erheblich. Für klassische „Bare Metal“-Installationen bietet Informix einen grafischen Installer sowie eine Silent-Install-Option für automatisierte Rollouts in großen Serverfarmen.
Nach der Installation ist die Konfiguration der „Onconfig“-Datei der wichtigste Schritt. Hier werden Parameter wie Speicherzuweisung (SHMTOTAL), CPU-Nutzung und Logging-Optionen festgelegt. Ein großer Vorteil von Informix ist, dass viele dieser Parameter dynamisch angepasst werden können, ohne den Server neu zu starten. Dies ist ein entscheidender Faktor für die 24/7-Verfügbarkeit. Erste Schritte beinhalten meist das Anlegen von sogenannten „Dbspaces“ – logischen Containern für die physischen Daten – und das Starten der Engine mit dem Befehl `oninit`.
- → Wählen Sie die passende Edition (Community, Innovator-C, Choice, Growth oder Enterprise).
- → Nutzen Sie Docker für schnelle Entwicklungs- und Testumgebungen.
- → Achten Sie auf die korrekte Konfiguration des Shared Memory, um Paging zu vermeiden.
- → Verwenden Sie das Tool `onstat`, um den Status der Engine in Echtzeit zu überwachen.
Sobald die Datenbank läuft, stellt sich die Frage nach der langfristigen Performance. Informix ist zwar von Haus aus schnell, aber mit dem richtigen Tuning lässt sich noch deutlich mehr aus der Hardware herausholen, was uns zum nächsten Kapitel führt.
Optimierung und Performance-Tuning
Performance-Tuning in IBM Informix ist eine Kunst für sich, die jedoch durch exzellente Werkzeuge unterstützt wird. Das Ziel ist es, Engpässe bei CPU, Speicher und I/O zu minimieren. Da Informix eine Multithreaded-Architektur besitzt, ist die optimale Verteilung der virtuellen Prozessoren (VPs) auf die physischen Kerne des Servers essenziell. Durch das Setzen der richtigen Anzahl an CPU-VPs kann das System parallel hunderte von Abfragen gleichzeitig bearbeiten, ohne dass es zu Kontextwechseln kommt, die die Leistung drosseln könnten.
Ein zentraler Aspekt des Tunings ist der Optimizer. Informix nutzt einen kostenbasierten Optimizer, der entscheidet, welcher Pfad für eine SQL-Abfrage der effizienteste ist (z.B. Index Scan vs. Sequential Scan). Damit der Optimizer korrekte Entscheidungen treffen kann, müssen die Statistiken der Tabellen aktuell sein. Der Befehl `UPDATE STATISTICS` ist hier das wichtigste Werkzeug. In modernen Versionen von Informix gibt es das „Auto Update Statistics“ (AUS) Feature, das diese Aufgabe automatisiert im Hintergrund erledigt, wenn die Systemlast niedrig ist.
Ein weiteres mächtiges Feature ist der „Informix Warehouse Accelerator“ (IWA). Diese Technologie nutzt In-Memory-Spaltenspeicherung und massive Parallelverarbeitung, um komplexe analytische Abfragen um das Hundert- oder sogar Tausendfache zu beschleunigen. Während transaktionale Daten (OLTP) weiterhin in der klassischen Engine liegen, werden analytische Daten (OLAP) in den IWA gespiegelt. Abfragen erkennen automatisch, welcher Speicherort schneller ist. Dies ermöglicht Hybrid Transactional/Analytical Processing (HTAP) auf höchstem Niveau, ohne dass Daten mühsam in ein separates Data Warehouse extrahiert werden müssen.
Neben der reinen Geschwindigkeit ist in der heutigen Zeit die Sicherheit der Daten von existenzieller Bedeutung. Performance bringt wenig, wenn die Daten nicht vor unbefugtem Zugriff geschützt sind. Daher widmen wir uns im nächsten Abschnitt den Sicherheits- und Compliance-Features von Informix.
Sicherheit und Compliance

Sicherheit ist bei IBM Informix tief in der DNA verwurzelt. In Zeiten von DSGVO und immer häufigeren Cyberangriffen bietet Informix ein umfassendes Arsenal an Schutzmechanismen. Dies beginnt bei der Verschlüsselung: „Encryption at Rest“ sorgt dafür, dass Daten auf den Festplatten verschlüsselt sind, sodass sie selbst bei physischem Diebstahl der Datenträger unlesbar bleiben. „Encryption in Transit“ schützt die Kommunikation zwischen Client und Server mittels TLS/SSL-Protokollen vor dem Abhören (Man-in-the-Middle-Angriffe).
Ein besonders wichtiges Feature für die Compliance ist das „Auditing“. Informix kann jede Aktion innerhalb der Datenbank lückenlos protokollieren – wer hat wann auf welche Daten zugegriffen oder diese verändert? Diese Audit-Logs sind manipulationssicher und essenziell für Unternehmen in regulierten Branchen wie dem Finanz- oder Gesundheitswesen. Darüber hinaus ermöglicht die „Role Based Access Control“ (RBAC) eine feingranulare Vergabe von Berechtigungen. Anstatt Benutzern pauschal Zugriff zu gewähren, können Rechte exakt auf Tabellen-, Spalten- oder sogar Zeilenebene definiert werden.
Zusätzlich bietet Informix Funktionen wie „Label-Based Access Control“ (LBAC). Hiermit können Daten mit Sicherheitslabels versehen werden. Ein Benutzer sieht dann nur die Zeilen, für die er die entsprechende Sicherheitsfreigabe besitzt. Dies ist ideal für Multi-Tenant-Anwendungen, bei denen verschiedene Kunden in derselben Datenbank arbeiten, aber strikt voneinander getrennt bleiben müssen. Laut BSI sind solche Mechanismen ein Kernbestandteil moderner IT-Sicherheitsarchitekturen.
- → Aktivieren Sie TLS 1.3 für alle Client-Verbindungen.
- → Implementieren Sie eine strenge Passwort-Policy über PAM (Pluggable Authentication Modules).
- → Nutzen Sie die Spaltenverschlüsselung für sensible Daten wie Kreditkartennummern.
- → Führen Sie regelmäßige Sicherheits-Audits mit den integrierten Tools durch.
Nachdem die Sicherheit gewährleistet ist, stellt sich für viele Unternehmen die Frage, wie sie ihre lokalen Informix-Instanzen in die moderne Cloud-Welt überführen können. Dies ist das Thema unseres nächsten Kapitels.
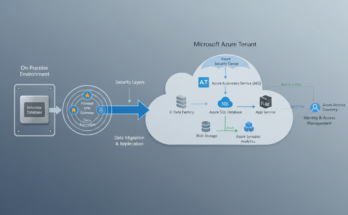
Cloud-Integration und Migration

Der Weg in die Cloud ist für moderne Unternehmen unvermeidlich, und IBM Informix macht diesen Übergang so reibungslos wie möglich. Informix ist „Cloud Native“ konzipiert und lässt sich in allen großen Cloud-Umgebungen wie IBM Cloud, AWS, Azure oder Google Cloud Platform (GCP) betreiben. Dabei haben Unternehmen die Wahl zwischen verschiedenen Modellen: IaaS (Infrastructure as a Service), bei dem sie die volle Kontrolle über das Betriebssystem behalten, oder containerisierte Lösungen via Red Hat OpenShift.
Ein entscheidender Vorteil bei der Migration ist die Binärkompatibilität. In vielen Fällen können Datenbank-Instanzen einfach per Backup & Restore von einem On-Premise-Server in die Cloud verschoben werden, ohne dass das Schema oder der Code der Anwendung geändert werden muss. Für minimale Ausfallzeiten bietet sich die Replikation an: Man setzt eine Informix-Instanz in der Cloud als Secondary-Server auf, synchronisiert die Daten in Echtzeit und führt dann einen kontrollierten Schwenk (Switchover) durch. Dies reduziert die Downtime auf wenige Sekunden.
Die Integration in hybride Cloud-Szenarien ist eine weitere Stärke. Informix kann Daten nahtlos zwischen lokalen Standorten und der Cloud austauschen. Dank der Enterprise Replication (ER) können Unternehmen Daten geografisch verteilen, um Latenzen für globale Nutzer zu minimieren oder gesetzliche Anforderungen an die Datenspeicherung (Data Residency) zu erfüllen. Laut einer Studie von Statista nutzen bereits über 90% der großen Unternehmen Multi-Cloud-Strategien, und Informix passt perfekt in dieses Ökosystem.
Mit der Cloud-Fähigkeit ist die technische Basis gelegt. Doch wie sieht der Alltag mit Informix aus? Im nächsten Abschnitt teilen wir wertvolle Tipps aus der Praxis.
Praktische Tipps und Best Practices
In jahrzehntelanger Arbeit mit IBM Informix haben sich bestimmte Best Practices herauskristallisiert, die den Unterschied zwischen einem stabilen System und einer permanenten Baustelle ausmachen. Der wichtigste Rat lautet: Automatisierung ist Ihr bester Freund. Nutzen Sie Scripts für tägliche Aufgaben wie Konsistenzprüfers (`oncheck`), Statistiken-Updates und Speicherüberwachung. Ein gut gewartetes Informix-System kann jahrelang ohne manuellen Eingriff laufen, aber nur, wenn die automatisierten Routinen sauber aufgesetzt sind.
Ein oft vernachlässigter Punkt ist das Monitoring des Logical Logs. Wenn diese vollaufen, friert die Datenbank ein, um die Datenintegrität zu schützen. Implementieren Sie ein automatisches Backup der Logs (z.B. mit `ALARMprogram`), um sicherzustellen, dass immer genügend Platz für neue Transaktionen vorhanden ist. Ebenso sollten Sie die „Temporary Dbspaces“ im Auge behalten. Komplexe Sortiervorgänge oder Joins benötigen temporären Platz; ist dieser zu klein, leidet die Performance massiv.
Für Entwickler gilt: Nutzen Sie „Prepared Statements“. Dies schützt nicht nur vor SQL-Injection, sondern erlaubt es Informix auch, den Ausführungsplan im Cache zu behalten. Das spart wertvolle CPU-Zyklen bei häufig wiederkehrenden Abfragen. Zudem sollten Sie die Datentypen weise wählen. Informix bietet sehr spezifische Typen (wie SMALLINT, INT8 oder BIGINT), die bei korrekter Wahl den Index-Speicherplatz minimieren und die Cache-Effizienz erhöhen. Ein kleinerer Index bedeutet weniger I/O und damit eine schnellere Antwortzeit.
Checkliste für den stabilen Betrieb
- → Tägliche Überprüfung der `online.log` auf Fehlermeldungen.
- → Wöchentliche `oncheck -cc` und `-cd` Läufe zur Validierung der Kataloge und Daten.
- → Einsatz von Monitoring-Tools wie Nagios oder Zabbix via SNMP-Schnittstelle.
- → Regelmäßiges Testen der Disaster-Recovery-Szenarien.
Mit diesen Tipps sind Sie bestens gerüstet. Kommen wir nun zum abschließenden Fazit und der Frage, ob Informix auch in Zukunft die richtige Wahl bleibt.
Fazit: Informix in 2026 einsetzen

Zusammenfassend lässt sich sagen, dass IBM Informix auch im Jahr 2026 eine beeindruckende Relevanz besitzt. Es ist die seltene Kombination aus jahrzehntelanger Stabilität und modernster Innovationskraft. Während viele „Hype-Datenbanken“ kommen und gehen, bleibt Informix ein Fels in der Brandung, der sich kontinuierlich anpasst. Die Fähigkeit, IoT-Datenströme, JSON-Dokumente und klassische SQL-Transaktionen in einer einzigen, wartungsarmen Engine zu vereinen, ist heute wertvoller denn je.
Für Unternehmen, die auf Effizienz setzen, bietet Informix einen unschlagbaren Return on Investment (ROI). Die geringen Administrationskosten, gepaart mit der hohen Performance auf Standard-Hardware, machen es zu einer wirtschaftlich klugen Entscheidung. Ob in der Cloud, On-Premise oder am „Edge“ – Informix beweist, dass eine solide Architektur zeitlos ist. Die ständige Weiterentwicklung durch IBM garantiert zudem, dass auch zukünftige Trends wie Künstliche Intelligenz und Machine Learning durch integrierte Funktionen optimal unterstützt werden.
Wer eine Datenbank sucht, die einfach funktioniert, extrem schnell skaliert und höchste Sicherheitsstandards erfüllt, kommt an IBM Informix nicht vorbei. Es ist nicht nur eine Datenbank für heute, sondern eine Investition in die digitale Infrastruktur von morgen. In einer Welt, in der Daten das neue Gold sind, ist Informix der Tresor, der sie nicht nur sicher verwahrt, sondern auch jederzeit blitzschnell verfügbar macht.
Wir hoffen, dieser detaillierte Einblick hat Ihnen geholfen, die Stärken und Einsatzmöglichkeiten von IBM Informix besser zu verstehen. Wenn Sie bereit sind, Ihre Datenstrategie auf das nächste Level zu heben, ist jetzt der ideale Zeitpunkt, sich intensiver mit dieser leistungsstarken Datenbank zu beschäftigen.